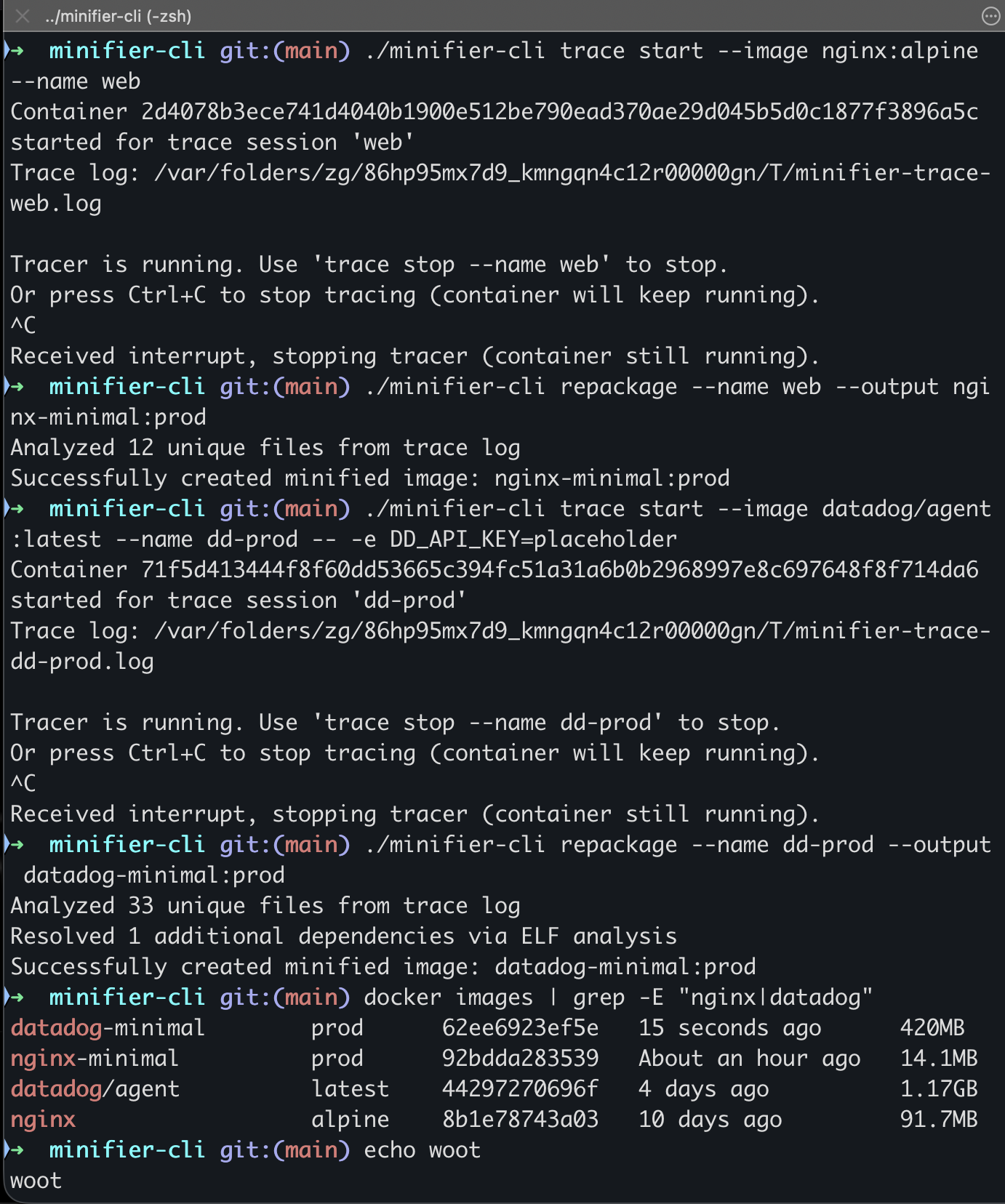
I do all my own vehicle maintenance.. two trucks, an ATV, a RZR.. which is also why wrenchtron exists. I’ve put in a ton of workbench time on microprocessors and robotics over the years.. Arduinos, Raspberry Pis, Android breakout boards, a lot of SparkFun parts bins.. and that’s honestly more the motivation here than anything from my engineering background. So when I started poking at “what could I actually build instead of just buying more aftermarket parts,” the answer that stuck wasn’t a new product idea. It was a question: why does every vehicle diagnostic gadget on the market give you a live number and nothing else?
I have a Peloton. I’ve gotten into running lately, and the app’s outdoor mode does something I take for granted until I think about it: my phone is the sensor. It initiates the session, logs the whole thing, and hands me back a history with real overlays.. not just “you’re running 7:15 pace right now,” gone the second I glance away.
Every belt-temp gauge I found for a UTV clutch is the opposite of that. A live LED readout, and nothing else. No history, no session, no export. You watch a number, and the second you look away, that data point is gone forever.
Sensing Without Sensor Hardware
Don’t build sensor hardware. Everyone already sells it.. probes, thermocouples, BLE thermometers by the dozen, built for smokers and ovens. What’s missing is the software layer that turns a live number into a session: connect, record, ride, and get something back afterward. Phone-initiated sensing instead of a dash gadget you have to be staring at when it matters.
And it doesn’t need an app store or a backend to prove that out. Web Bluetooth plus a PWA gets you a phone-first tool with zero install friction and zero servers.
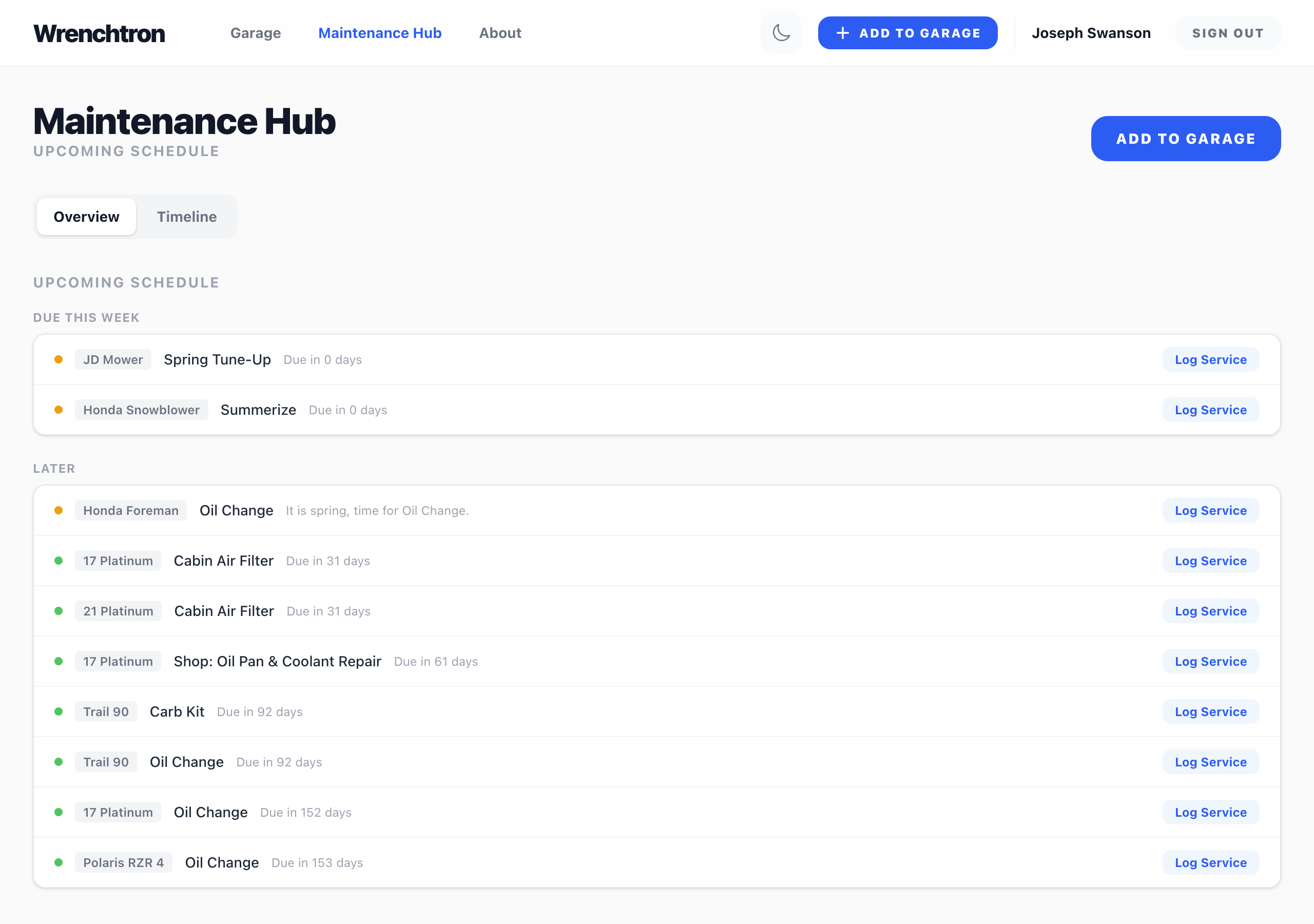
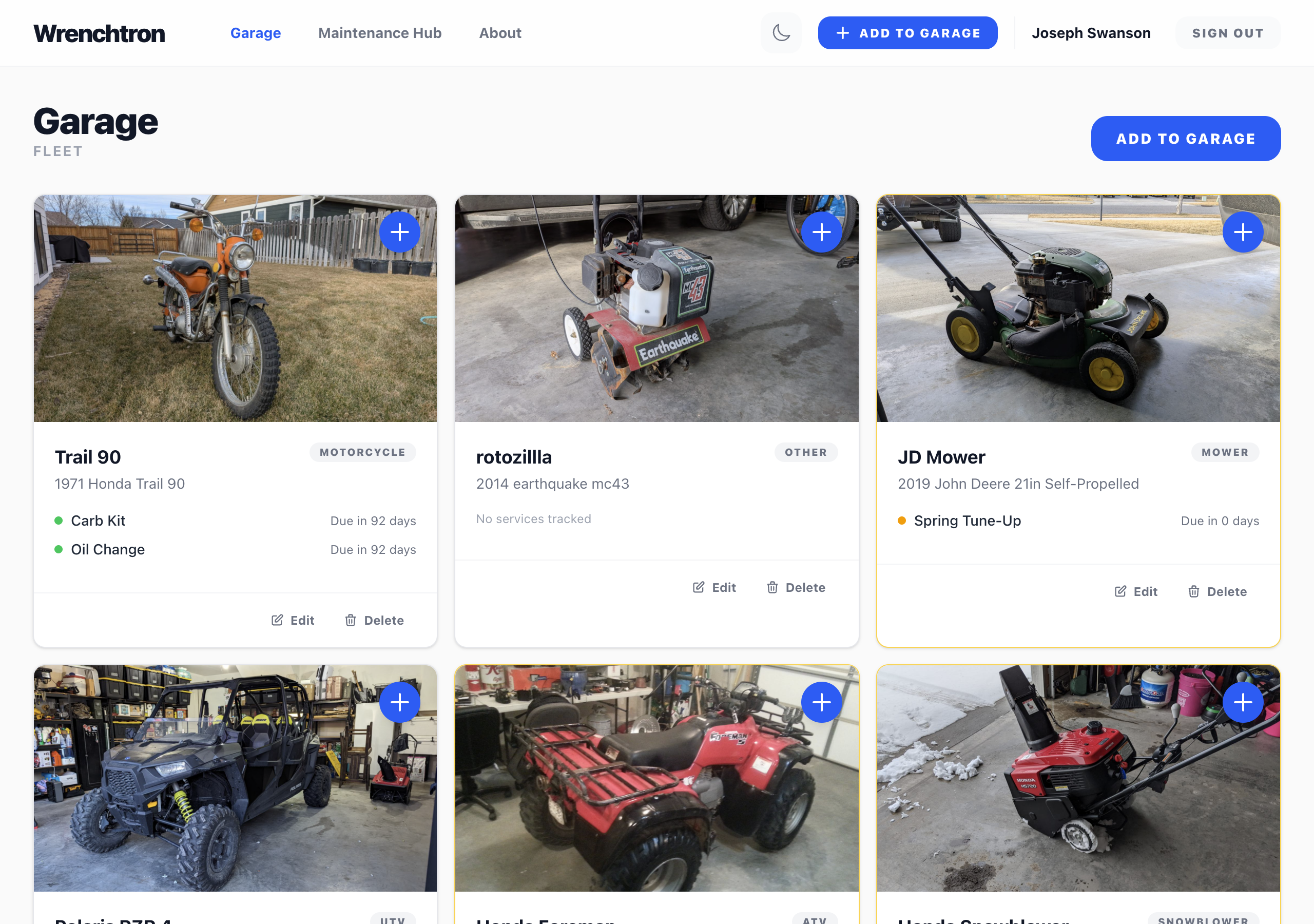
What I Built
utvtron is a Next.js static export, output: 'export', no backend, deployed to Vercel.. everything lives in the browser. Web Bluetooth talks to the probe directly, localStorage holds the session history, no accounts, nothing leaves the phone.
The hardware is a ThermoPro TP25.. a $30 BLE meat thermometer, not anything purpose-built for a vehicle. Getting it talking to a browser meant reverse-engineering its GATT protocol, which nobody publishes officially. I leaned on a community project (thermopro-cli) that decompiled the Android app to document the handshake bytes and a BCD-encoded temperature format I’d never have guessed at from scratch. First real connection, the app read 66°F next to the probe’s own controller reading 66°F.. the moment the whole “phone as sensor hub” idea stopped being theoretical.
The loop itself is deliberately narrow: connect → start session → live readout while recording → stop → history with a chart and CSV export. That’s it. No G-force, no GPS overlay, no multi-vehicle profiles.. none of that is worth building until the core loop proves useful across a real season of use.
First Real Ride
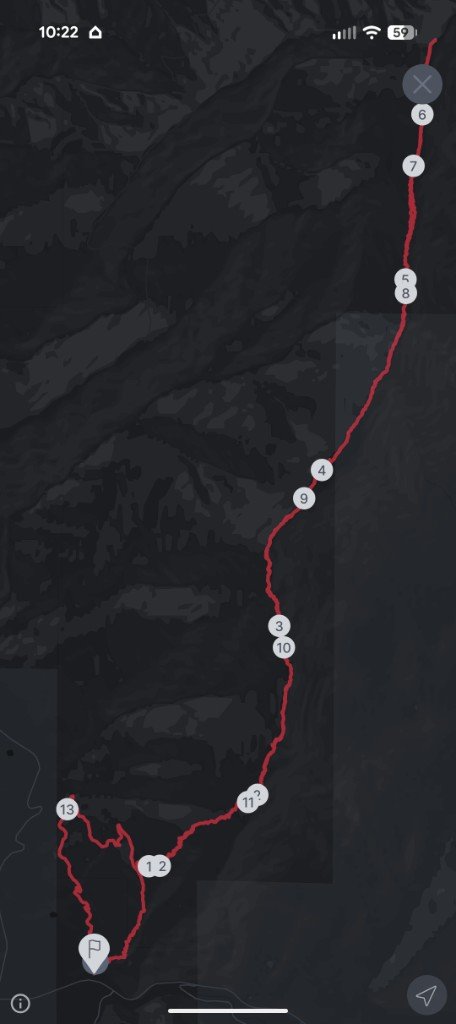
I mounted the probe behind the back seat.. not the right spot, more on that below.. and took it out for real.

36 minutes, live temp readout the whole time, saved cleanly to history afterward with a chart and an export.
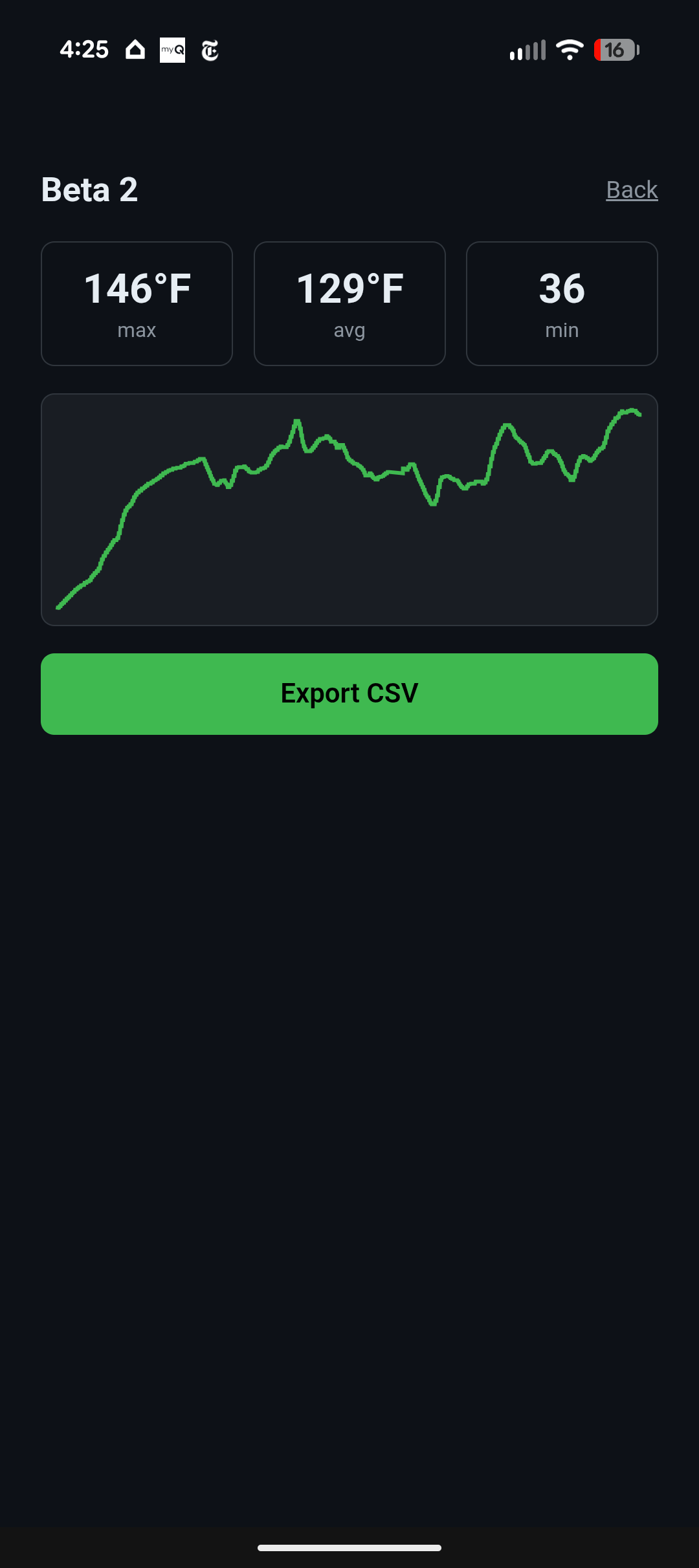
The best part wasn’t the chart. It was what the raw CSV timestamps caught. About 20 minutes in, there’s a ~50 second gap in the data, followed by 33 readings that all share the exact same millisecond timestamp even though the temperature values are clearly changing across them. That’s not a sensor glitch.. it’s the phone’s screen locking mid-ride, throttling the browser tab’s timers, while the OS Bluetooth stack kept buffering notifications in the background. When the tab woke back up, a whole backlog of queued readings landed in the same JS tick at once. Real bug, only visible because I had real ride data to stare at.
I also had an accidental ground truth: the RZR’s own dash cycles through a coolant temp readout, and I happened to photograph it a few times through the ride.. climbing from 183°F to 206°F over the same window the probe climbed from 127°F to a peak of 146°F. Different subsystems, same physically-consistent upward trend.


And at the very end, I moved the probe into the engine bay and read 142°F straight off the ThermoPro controller’s own screen.. matching the app’s last logged readings almost exactly. Good confirmation the Bluetooth data itself was trustworthy; the bug was purely a phone-timing artifact, not a bad sensor.

Fixed with a Screen Wake Lock during recording, detection for an unexpected BLE disconnect instead of silently going dark, and autosaving in-progress sessions every 10 seconds so a killed tab doesn’t cost you the whole ride.
Where This Might Go
To be clear about what this is not, yet: a solved CVT belt-monitoring tool. The RZR’s factory gauge only exposes coolant temp.. there’s no OEM visibility into the belt or clutch at all, which is the actual gap that got me interested in this in the first place. This ride proved the tool works. It didn’t prove anything about the belt, because the probe was sitting behind a seat, not in the clutch exhaust duct where the real signal lives.
That’s the next ride: get the probe into the duct, and see if a $30 thermometer and an afternoon of Web Bluetooth can tell me something the factory dash genuinely can’t.
What This Isn’t, Yet
- Not a product. This is a build log, not a pitch. No pricing, no roadmap, no App Store link.
- The sensor placement that matters hasn’t happened yet. Everything above is “the tool works,” not “the belt is fine” or “the belt is cooking.”
- Wake Lock isn’t bulletproof. It stops the screen from sleeping; it doesn’t stop you from manually switching apps mid-ride. Autosave is the actual safety net.
- Source stays private for now. Unlike the fleet tools above, I haven’t ruled out selling this one, so the repo isn’t public.. the process is the point of this post, not the implementation.
Try It
Live: utvtron.vercel.app.. Chrome on Android only, Web Bluetooth isn’t there yet on iOS Safari.
Source stays closed for the moment. More once the probe’s somewhere that actually tells me something.